

Exemplos De Engine De Processamento De Big Data, a capacidade de analisar quantidades gigantescas de dados se tornou fundamental para empresas de todos os setores. No mundo digital de hoje, dados são gerados em uma velocidade sem precedentes, criando um mar de informações que pode ser usado para obter insights valiosos e impulsionar a tomada de decisões estratégicas.
Mas lidar com esse volume colossal de dados apresenta desafios únicos, exigindo ferramentas e técnicas especializadas para processamento e análise eficiente. As Engines de Processamento de Big Data surgem como soluções poderosas para extrair valor do Big Data, permitindo que empresas transformem dados brutos em informações acionáveis.
Essas engines são projetadas para lidar com a complexidade e o volume de dados em grande escala, oferecendo recursos avançados de processamento, armazenamento e análise. Através de arquiteturas e algoritmos sofisticados, elas permitem que empresas explorem padrões ocultos, identifiquem tendências emergentes e otimizem operações de maneira sem precedentes.
Seja para análise de dados de clientes, otimização de cadeias de suprimentos, detecção de fraudes ou previsão de tendências do mercado, as Engines de Processamento de Big Data desempenham um papel crucial na era digital, impulsionando a inovação e a competitividade.
Introdução
A era digital é caracterizada pela explosão de dados, e a capacidade de processar e analisar esses dados, conhecidos como Big Data, tornou-se crucial para o sucesso de empresas e organizações. O Big Data apresenta desafios únicos, como o volume massivo de dados, a velocidade com que são gerados e a variedade de formatos.
Lidar com esses desafios exige soluções especializadas que possibilitem a extração de insights valiosos e a tomada de decisões estratégicas.
Vantagens de utilizar Engines de Processamento de Big Data
As Engines de Processamento de Big Data surgem como ferramentas poderosas para lidar com os desafios do Big Data. Essas plataformas são projetadas para processar grandes volumes de dados em tempo real, utilizando algoritmos avançados e técnicas de análise. As principais vantagens de utilizar Engines de Processamento de Big Data incluem:
- Análise em tempo real:As Engines de Processamento de Big Data permitem analisar dados em tempo real, proporcionando insights imediatos sobre tendências, padrões e eventos. Isso é crucial para tomada de decisões rápidas e eficazes em cenários dinâmicos.
- Processamento de dados complexos:Essas plataformas podem lidar com dados estruturados, semiestruturados e não estruturados, abrangendo uma ampla variedade de fontes e formatos. Isso permite análises abrangentes de dados heterogêneos.
- Escalabilidade:As Engines de Processamento de Big Data são projetadas para escalar horizontalmente, adicionando mais recursos computacionais conforme necessário. Isso garante que o processamento de dados seja eficiente, mesmo com volumes massivos de dados.
- Insights e previsões:Através da análise de grandes volumes de dados, as Engines de Processamento de Big Data podem identificar padrões e tendências que seriam difíceis de detectar manualmente. Isso permite gerar insights valiosos e realizar previsões precisas sobre eventos futuros.
- Otimização de processos:As informações extraídas das análises de Big Data podem ser utilizadas para otimizar processos, melhorar a eficiência operacional e reduzir custos. Por exemplo, empresas podem utilizar essas informações para personalizar ofertas, melhorar a experiência do cliente e otimizar cadeias de suprimentos.
Arquitetura de Engines de Processamento de Big Data

A arquitetura de uma engine de processamento de Big Data é fundamental para lidar com o volume, a variedade e a velocidade dos dados. Ela define como os dados são coletados, armazenados, processados e analisados.
Componentes Principais de uma Arquitetura de Big Data
A arquitetura de uma engine de Big Data geralmente é composta por vários componentes que trabalham em conjunto para processar dados de forma eficiente. Esses componentes podem variar dependendo da engine específica, mas alguns dos mais comuns incluem:
- Coleta de Dados:O primeiro passo é coletar os dados de várias fontes, como bancos de dados, logs de aplicativos, sensores, redes sociais, etc. Essa coleta pode ser feita em tempo real ou em lotes, dependendo dos requisitos do sistema.
- Armazenamento de Dados:Os dados coletados são armazenados em sistemas de armazenamento de dados distribuídos, como Hadoop Distributed File System (HDFS) ou Amazon S3. Esses sistemas são projetados para lidar com grandes volumes de dados e fornecer acesso rápido e confiável.
- Processamento de Dados:Os dados armazenados são processados usando frameworks de processamento distribuído, como Apache Spark, Apache Flink ou Apache Hadoop. Esses frameworks dividem os dados em partes menores e processam cada parte em paralelo em vários nós, acelerando o tempo de processamento.
- Análise de Dados:Após o processamento, os dados são analisados para extrair insights valiosos. Isso pode incluir análise exploratória de dados, modelagem preditiva, análise de sentimentos, etc. As ferramentas de análise de dados podem incluir ferramentas de visualização, plataformas de aprendizado de máquina e sistemas de inteligência de negócios.
Interação entre os Componentes
Os componentes da arquitetura de Big Data interagem entre si de forma integrada para processar os dados. O fluxo de dados típico é o seguinte:
- Coleta:Os dados são coletados de várias fontes e enviados para o sistema de armazenamento.
- Armazenamento:Os dados são armazenados em um sistema de armazenamento distribuído, como HDFS ou S3.
- Processamento:Os dados são processados por frameworks de processamento distribuído, como Spark ou Hadoop. Esse processamento pode incluir limpeza, transformação, agregação e outras operações.
- Análise:Os dados processados são analisados usando ferramentas de análise de dados para gerar insights e relatórios.
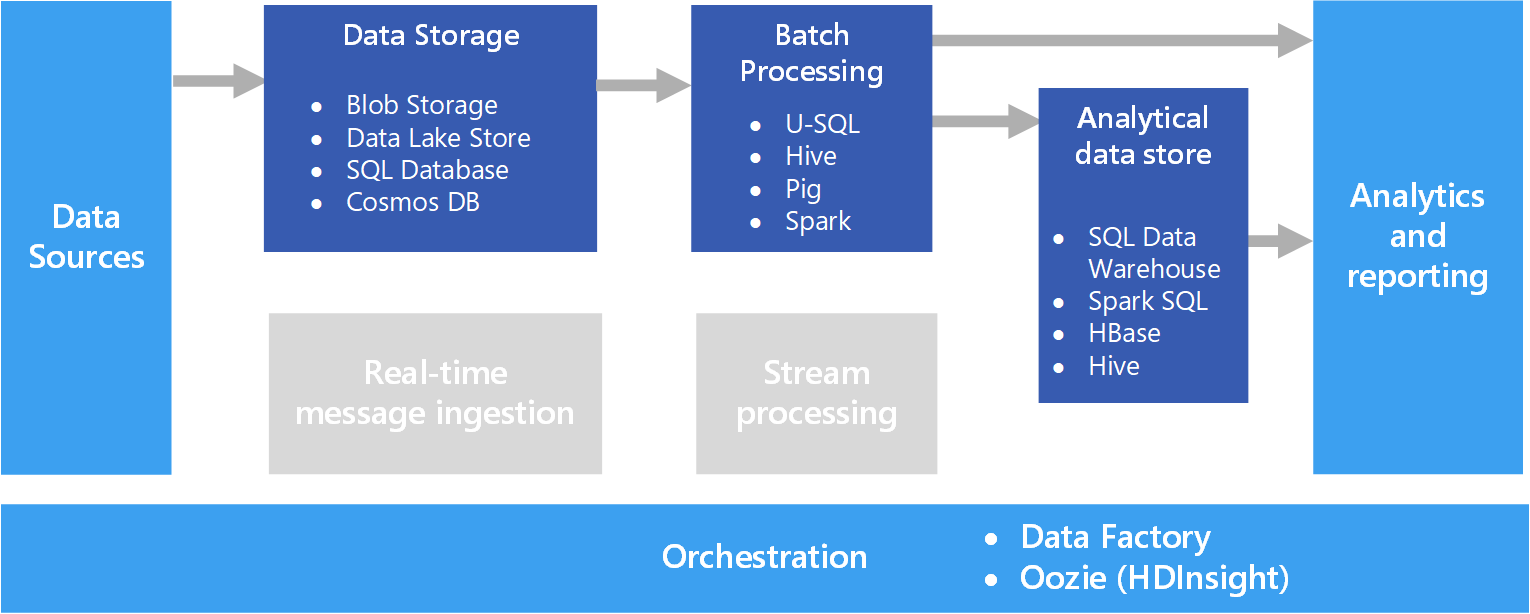
Diagrama de Blocos
Um diagrama de blocos que ilustra a arquitetura de uma engine de Big Data:
[Diagrama de Blocos:Bloco 1
Coleta de Dados (fontes de dados, mecanismos de coleta)
Bloco 2
Armazenamento de Dados (sistemas de armazenamento distribuídos, como HDFS ou S3)
Bloco 3
Processamento de Dados (frameworks de processamento distribuído, como Spark ou Hadoop)
Bloco 4
Análise de Dados (ferramentas de análise, visualização e aprendizado de máquina)]
Casos de Uso de Engines de Processamento de Big Data
As Engines de Processamento de Big Data são ferramentas poderosas que permitem às empresas extrair valor de grandes volumes de dados. Esses sistemas são capazes de lidar com dados estruturados e não estruturados, além de realizar análises complexas em tempo real.
Varejo, Exemplos De Engine De Processamento De Big Data
No varejo, as Engines de Big Data são usadas para entender melhor o comportamento do cliente, otimizar as operações da cadeia de suprimentos e personalizar a experiência de compra.
- Análise de Sentimentos:As empresas podem analisar dados de mídias sociais e avaliações de produtos para entender o que os clientes pensam sobre seus produtos e serviços. Essa informação pode ser usada para melhorar a qualidade dos produtos e serviços, bem como para criar campanhas de marketing mais eficazes.
- Recomendações Personalizadas:As Engines de Big Data podem ser usadas para analisar dados de compras anteriores, histórico de navegação e preferências do cliente para fornecer recomendações personalizadas de produtos. Isso pode levar a um aumento nas vendas e na fidelidade do cliente.
- Gestão de Estoque:As Engines de Big Data podem ajudar as empresas a prever a demanda por produtos e otimizar seus níveis de estoque. Isso pode reduzir os custos de estoque e evitar perdas devido a produtos vencidos ou estoques insuficientes.
Tecnologias de Big Data mais utilizadas no Varejo:Hadoop, Spark, Hive, Cassandra, MongoDB, Elasticsearch.
Saúde
No setor da saúde, as Engines de Big Data são usadas para melhorar o atendimento ao paciente, realizar pesquisas médicas e desenvolver novos medicamentos.
- Diagnóstico e Tratamento Personalizados:As Engines de Big Data podem analisar dados de pacientes, como histórico médico, exames e dados genéticos, para identificar padrões e desenvolver diagnósticos e planos de tratamento personalizados. Isso pode levar a melhores resultados de saúde e custos mais baixos.
- Prevenção de Doenças:As Engines de Big Data podem ser usadas para analisar dados de saúde populacional para identificar fatores de risco para doenças e desenvolver estratégias de prevenção. Isso pode ajudar a reduzir a incidência de doenças e melhorar a saúde pública.
- Descoberta de Medicamentos:As Engines de Big Data podem ser usadas para analisar grandes conjuntos de dados de pesquisa médica para identificar potenciais novos alvos de medicamentos e desenvolver novos tratamentos. Isso pode levar a avanços na pesquisa médica e ao desenvolvimento de novos medicamentos mais eficazes.
Tecnologias de Big Data mais utilizadas na Saúde:Hadoop, Spark, Hive, Cassandra, MongoDB, Elasticsearch, TensorFlow.
Finanças
No setor financeiro, as Engines de Big Data são usadas para detectar fraudes, gerenciar riscos, fornecer análises de mercado e melhorar a tomada de decisões.
- Detecção de Fraudes:As Engines de Big Data podem analisar dados de transações financeiras em tempo real para identificar padrões suspeitos e detectar fraudes. Isso pode ajudar as instituições financeiras a proteger seus clientes e seus próprios ativos.
- Gerenciamento de Riscos:As Engines de Big Data podem ser usadas para analisar dados de mercado e dados de clientes para identificar e gerenciar riscos financeiros. Isso pode ajudar as instituições financeiras a tomar decisões mais informadas e proteger seus investimentos.
- Análise de Mercado:As Engines de Big Data podem analisar dados de mercado, como preços de ações, notícias financeiras e dados econômicos, para fornecer insights sobre tendências do mercado e oportunidades de investimento. Isso pode ajudar os investidores a tomar decisões mais informadas e obter melhores retornos.
Tecnologias de Big Data mais utilizadas nas Finanças:Hadoop, Spark, Hive, Cassandra, MongoDB, Elasticsearch, TensorFlow, Apache Kafka.
Tendências Futuras em Engines de Processamento de Big Data: Exemplos De Engine De Processamento De Big Data
O mundo dos dados está em constante evolução, impulsionado por novas tecnologias e demandas crescentes por insights. As Engines de Processamento de Big Data, ferramentas essenciais para lidar com a avalanche de informações, também estão se adaptando a essa realidade.
Com o avanço da computação em nuvem, da inteligência artificial e da Internet das Coisas, o futuro do processamento de Big Data promete ser ainda mais inovador e desafiador.
Impacto da Computação em Nuvem
A computação em nuvem revolucionou a forma como as empresas acessam e processam dados. A escalabilidade, flexibilidade e custo-benefício da nuvem tornaram-se fatores decisivos na escolha de Engines de Big Data.
- Plataformas como AWS, Azure e Google Cloud oferecem uma gama de serviços de Big Data, incluindo armazenamento, processamento e análise.
- A computação sem servidor (serverless) permite que os usuários paguem apenas pelo tempo de processamento realmente utilizado, reduzindo custos e otimizando recursos.
- A infraestrutura em nuvem permite a implementação rápida de soluções de Big Data, sem a necessidade de investimentos em hardware e software.
O Papel da Inteligência Artificial
A inteligência artificial (IA) está transformando a maneira como as Engines de Big Data são usadas. A IA permite a automatização de tarefas complexas, a descoberta de padrões ocultos e a criação de modelos preditivos mais precisos.
- Algoritmos de Machine Learning, como redes neurais e árvores de decisão, são usados para analisar dados em tempo real e gerar insights acionáveis.
- A IA facilita a criação de sistemas de recomendação personalizados, otimizando a experiência do usuário e aumentando as vendas.
- A análise de dados com IA permite a detecção de fraudes, a previsão de falhas em equipamentos e a otimização de processos de negócios.
Internet das Coisas e o Crescimento Exponencial de Dados
A Internet das Coisas (IoT) está gerando uma quantidade massiva de dados, criando um desafio e uma oportunidade para as Engines de Big Data.
- Dispositivos conectados geram dados em tempo real, exigindo soluções de processamento de alta velocidade e baixo tempo de latência.
- As Engines de Big Data são usadas para analisar dados de IoT, monitorar o desempenho de dispositivos, otimizar a eficiência de processos e identificar novas oportunidades de negócio.
- A análise de dados de IoT permite a criação de cidades inteligentes, sistemas de agricultura de precisão e novas soluções para a indústria 4.0.
Previsões sobre o Futuro do Processamento de Big Data
- As Engines de Big Data se tornarão cada vez mais especializadas, com foco em tarefas específicas, como processamento de streaming, análise gráfica ou processamento de linguagem natural.
- A integração com a IA e o Machine Learning será cada vez mais profunda, permitindo a criação de sistemas de Big Data autônomos e inteligentes.
- A segurança de dados se tornará uma prioridade crucial, com foco na proteção de informações confidenciais e na conformidade com regulamentações como a GDPR.
Em resumo, as Engines de Processamento de Big Data representam uma ferramenta essencial para empresas que desejam extrair valor do Big Data. Sua capacidade de lidar com volumes massivos de dados, oferecer análise em tempo real e fornecer insights acionáveis permite que empresas tomem decisões mais inteligentes, otimizem operações, personalizem experiências do cliente e se adaptem às mudanças do mercado de forma mais eficaz.
O futuro do Big Data é promissor, impulsionado por avanços em inteligência artificial, computação em nuvem e internet das coisas. As Engines de Processamento de Big Data continuarão a evoluir, proporcionando novas oportunidades para empresas de todos os setores aproveitarem o poder dos dados para impulsionar o crescimento e o sucesso.